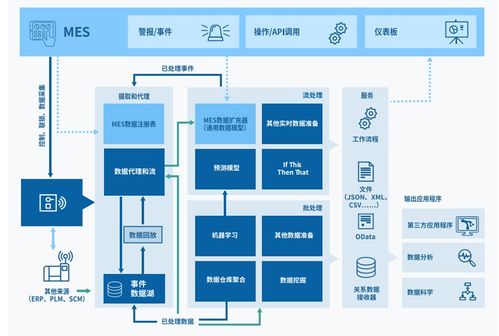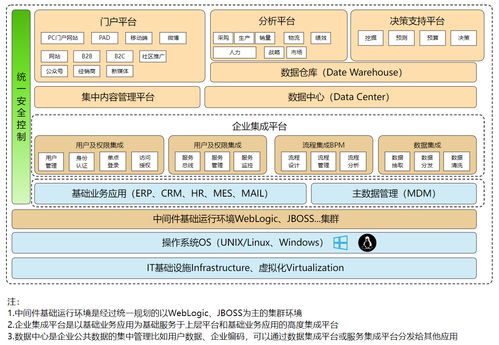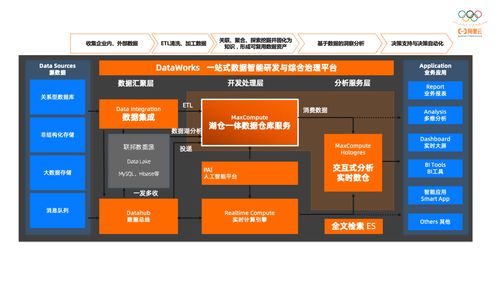
随着数据规模的指数级增长,半结构化数据(如JSON、XML、CSV等)已成为企业数据资产的重要组成部分。这类数据兼具结构化与非结构化的特性,其模式灵活多变,处理起来往往更具挑战性。阿里云MaxCompute作为领先的大数据计算平台,其强大的SQL引擎为高效处理半结构化数据提供了强有力的支持。本文将深入探讨基于MaxCompute SQL的半结构化数据处理与存储实践,以构建可靠的数据处理与存储支持服务。
一、半结构化数据的引入与存储策略
在MaxCompute中处理半结构化数据的第一步是将其引入计算平台。常见的做法包括:
- 数据同步:通过DataWorks的数据集成、Tunnel命令行工具或SDK,将存储在OSS、RDS等外部数据源的JSON、CSV等格式文件同步至MaxCompute。对于持续增量数据,可建立定期调度任务。
- 表定义优化:MaxCompute支持STRING、ARRAY、MAP等复杂数据类型,非常适合存储半结构化数据。例如,可以将整个JSON对象存储为单列STRING类型,或使用
JSON<em>TUPLE、GET</em>JSON_OBJECT等函数在查询时动态解析。对于模式相对固定或需要高频查询的部分,也可在同步过程中通过UDF或ETL任务将其“拍平”为标准的二维表结构,以换取极致的查询性能。
二、核心数据处理:MaxCompute SQL函数与技巧
MaxCompute SQL提供了一系列内置函数,专门用于半结构化数据的解析、转换与查询。
1. JSON数据处理:
* GET<em>JSON</em>OBJECT:从JSON字符串中提取指定路径下的标量值。这是最常用、最高效的函数之一。
`sql
SELECT GETJSONOBJECT(eventjson, '$.user.id') AS userid
FROM log_table;
`
* JSON<em>TUPLE:与GET</em>JSON<em>OBJECT类似,但能一次性提取多个路径的值,性能更优。
`sql
SELECT JSONTUPLE(eventjson, 'user.id', 'event.time') AS (userid, eventtime)
FROM logtable;
`
- 复杂类型处理:对于JSON中的数组或嵌套对象,可以结合
LATERAL VIEW与EXPLODE函数进行行转列操作,展开数组内的元素进行进一步分析。
- CSV/文本数据处理:
- 对于CSV或自定义分隔符的文本,可使用
REGEXP<em>EXTRACT、SPLIT</em>PART等字符串函数进行字段拆分。
- 结合
TRANSFORM子句或Python UDF,可以处理更复杂的非标准文本格式。
- 数据质量与清洗:在半结构化数据处理中,数据格式不一致、字段缺失是常见问题。利用
CASE WHEN、COALESCE、NVL等函数进行空值或异常值处理至关重要。在解析前使用TRY函数或编写健壮的UDF,可以有效避免因数据格式错误导致的作业失败。
三、构建数据处理与存储支持服务的最佳实践
为了将上述能力转化为稳定、可复用的服务,建议遵循以下实践:
- 分层设计与模型标准化:遵循数仓分层理念(如ODS、DWD、DWS、ADS),在ODS层以原始格式(STRING)或轻度解析后的复杂类型存储半结构化数据,在DWD层通过SQL解析、清洗、标准化,形成结构清晰、质量可靠的明细数据层。这确保了原始数据的可追溯性与下游使用的便捷性。
- 元数据管理与数据发现:建立半结构化数据字段的元数据登记册。记录JSON路径、字段含义、数据类型和样例,并可通过DataWorks的数据地图等功能进行管理,极大提升数据可见性和团队协作效率。
- 性能优化:
- 分区与聚类:对大数据表采用分区(如按日期
dt分区)和聚类(如对常用查询字段聚类)策略,能显著减少数据扫描量,提升查询速度。
- 列存储与压缩:MaxCompute默认采用高效的列存储和压缩格式,但对于STRING类型存储的巨型JSON对象,需注意其可能带来的IO压力,适时进行结构化解耦。
- 计算资源调优:对于复杂的解析和转换作业,合理设置作业的CPU、内存资源,可以避免长尾任务,保证整体处理时效。
- 自动化与调度:利用DataWorks等运维调度工具,将数据同步、解析、质量监控、任务依赖等流程编排成自动化的工作流。设置监控告警,确保数据处理服务的稳定运行和时效性达成。
- 安全与成本管控:通过MaxCompute的Project级、表级、列级权限体系,严格控制半结构化数据中敏感信息的访问权限。监控SQL的数据扫描量,优化SQL写法,避免全表扫描,有效控制计算成本。
四、与展望
通过MaxCompute SQL强大的内置函数和灵活的存储模型,企业能够高效地应对半结构化数据的处理挑战。成功的核心在于将离散的技术点(如JSON解析)系统化地融入到数据平台的服务体系中——即通过标准化的数据模型、自动化的处理流程、完善的元数据管理和持续的性能优化,构建起一个高可靠、高效率、易用的数据处理与存储支持服务。随着MaxCompute对半结构化数据支持能力的持续增强(如原生的SEMI-STRUCTURED数据类型、更强大的JSON函数库),这一实践将变得更加简洁和强大,进一步释放半结构化数据的业务价值。