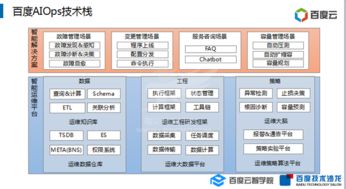
在智能推荐算法日益渗透数字生活的今天,用户享受着前所未有的个性化内容便利,却也深陷信息过载的漩涡。过量的、重复的、低质的信息推送不断消耗着用户的注意力与时间。要破解这一困局,单纯优化表层推荐算法往往治标不治本。回归根本,从数据处理与存储支持的底层架构入手,构建高效、智能的数据服务层,是构建下一代“智慧推荐”系统、实现信息“提质减量”的关键路径。
一、数据源治理:信息过载的第一道防线
信息过载的源头,常始于数据采集的“贪婪”与“无序”。因此,必须在数据入口处建立精细化的治理策略:
- 多源数据融合与去重:整合来自用户行为、内容属性、社交网络、第三方平台等多维数据源,利用实体识别、相似度计算等技术,在数据接入层实现跨源内容的深度去重与归一化,从根源上减少冗余信息流入系统。
- 数据质量实时评估与过滤:建立实时数据质量评估体系,对内容的原创性、权威性、完整性、时效性等维度进行打分。对于低质量、垃圾信息、虚假内容等,应在存储前进行标记或拦截,确保存入“数据湖”或“数据仓库”的是高价值“原料”。
- 兴趣粒度分层与冷启动优化:在数据采集时,不仅记录用户的显性点击,更应通过交互时长、完播率、深度互动等隐性信号,精细化刻画用户兴趣的强度与稳定性。为新用户或新内容设计专门的数据采集与快速通道,缓解冷启动带来的盲目推送问题。
二、存储架构革新:支撑高效数据服务的中枢
传统单一的存储方案已难以应对推荐系统对海量、异构、实时数据的处理需求。面向智能推荐的存储层需要具备以下特征:
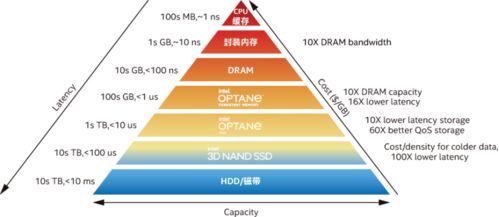
- 分层分级存储体系:采用“热-温-冷”数据分层策略。将高频访问的用户画像、实时行为流、热门内容索引存放在内存数据库(如Redis)或高性能SSD存储中,保障毫秒级响应;将温数据(如近期历史行为)存放于分布式数据库(如HBase, Cassandra);将冷数据(如长期归档内容)移至成本更低的对象存储。这种架构在保证性能的极大优化了存储成本。
- 向量化存储与检索的深度集成:随着嵌入(Embedding)技术成为推荐系统的核心,专门用于存储和检索高维向量数据的向量数据库(如Milvus, Pinecone)变得至关重要。它能将用户和内容的语义信息转化为向量并高效存储,支持基于相似度的毫秒级检索,是实现“更准、更巧”推荐而非“更多”推荐的算力基础。
- 统一的数据服务层(Data Serving Layer):在存储层之上,构建一个抽象、统一的实时数据服务接口。无论底层数据存放在何处,推荐引擎、特征工程、在线模型都能通过这一层以一致、低延迟的方式获取所需的用户特征、内容特征和上下文特征。这简化了系统复杂度,并使得数据更新(如用户兴趣漂移)能瞬间生效。
三、数据处理管道:驱动精准推荐的智能引擎
高效的数据处理管道是将原始数据转化为推荐智能的“生产线”。
- 流批一体的特征计算:结合Apache Flink等流处理框架和Spark等批处理框架,实现特征计算的流批一体。用户实时点击行为可秒级更新特征,用于即时推荐;而深度画像、模型训练则依赖可靠的批量计算。两者协同,确保推荐系统既敏捷又稳健。
- 自动化特征工程与元数据管理:利用自动化机器学习(AutoML)工具探索和生成有效的特征组合,并建立完善的特征元数据管理系统,追踪特征的来源、 lineage、统计信息和效用,避免无效特征堆积造成的数据噪声和计算浪费。
- 面向场景的模型数据仓:为不同的推荐场景(如信息流、商品推荐、视频推荐)构建独立的、高度优化的模型数据仓库。每个仓库中只存储和计算该场景最相关的特征和数据,实现数据与计算的“垂直化”,进一步提升处理效率和推荐精度。
###
信息过载的本质,是数据处理能力与信息生产速度之间的失衡。智能推荐系统不应成为信息洪流的简单放大器,而应成为帮助用户甄别、筛选、匹配价值的智能过滤器。这一目标的实现,离不开一个坚实、灵活、智能的数据与存储底层。通过源头治理保障数据质量,通过架构革新提升服务效能,通过智能管道驱动精准计算,我们方能从数据的“矿山”中炼出真正的“金子”,让推荐系统回归服务用户的本源,在纷繁的信息世界中为用户开辟一条清澈的认知航道。