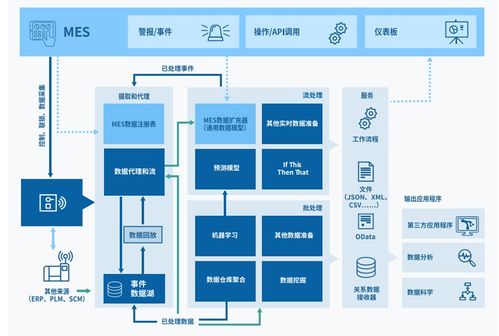
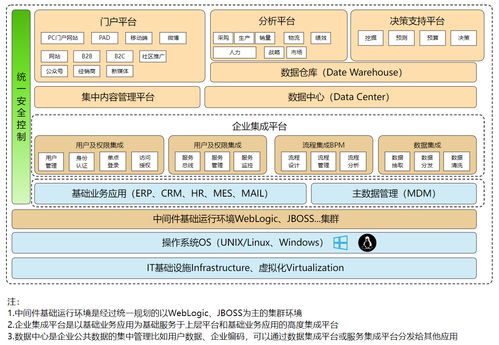
随着人工智能技术从实验室走向产业应用,科教领域正掀起一场以AI为核心的深刻变革。在这场变革中,一个清晰的共识正在形成:算力是驱动AI发展的引擎。因此,“懂行的都在卷算力”——高校、科研院所、科技企业纷纷投入巨资,竞相部署GPU集群、建设智算中心,力求在模型训练、数据分析等前沿探索中获得速度与规模优势。在算力军备竞赛的白热化阶段,一个更深层次、更关键的瓶颈逐渐浮出水面:数据处理与存储。
单纯堆砌算力,如同为超级跑车配备了强大的引擎,却行驶在颠簸狭窄的乡间小道上。海量的训练数据、复杂的模型参数、实时的推理请求,在产生惊人的计算吞吐量时,也对数据存储系统的性能、可靠性和扩展性提出了前所未有的挑战。传统基于机械硬盘(HDD)的存储架构,在I/O延迟、随机读写速度等方面已难以满足AI工作负载(尤其是训练阶段)对数据“即取即用”的严苛要求。数据供给的“断流”或“迟滞”,会导致昂贵的算力资源大量闲置,形成“算力空转”,严重拖慢整体科研与应用进程。
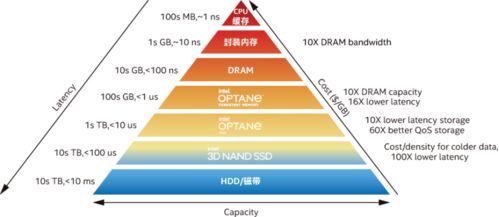
于是,更懂行、更具前瞻性的科教机构与团队,正将战略重点转向底层基础设施的全面升级,其核心举措之一便是 “升级全闪存储” 。全闪存阵列(AFA)以其极致的性能(微秒级延迟、超高IOPS和吞吐量)、先天的低功耗、静音特性以及日益优化的总拥有成本(TCO),正在成为支撑AI时代的存储基石。
在科教AI场景中,全闪存储的价值具体体现在:
- 加速模型训练与迭代:训练过程需要频繁地从海量数据集中随机读取小文件(如图片、文本片段)。全闪存储的高并发随机读取能力,能确保数据持续、高速地“喂”给GPU,将训练周期从天级缩短到小时级,极大提升科研效率。
- 赋能实时推理与交互:在AI教学平台、科研模拟、智慧校园等应用中,模型需要对外提供低延迟的推理服务。全闪存储能保证模型参数快速加载,并高效处理实时产生的交互数据,提供流畅的用户体验。
- 简化数据管理与Pipeline:AI项目涉及数据清洗、标注、多个版本模型与结果的存储管理。高性能的全闪存储可以统一承载这些混合负载,简化数据流水线,与计算平台更紧密协同。
- 保障关键研究数据安全与高可用:科研数据价值连城且不可复现。全闪存储通常配备企业级的数据保护功能,如快照、克隆、加密和跨站点复制,为珍贵的研究成果提供坚实保障。
数据处理和存储支持服务的智能化、专业化也随之成为刚需。这不仅仅是提供硬件,更包括:
- 定制化架构设计:根据特定的AI工作负载(如CV、NLP、科学计算)设计最优的存储架构(集中式、分布式、存算分离等)。
- 性能优化与调校:确保存储系统与计算框架(如TensorFlow, PyTorch)以及调度平台(如Kubernetes)深度适配,消除I/O瓶颈。
- 全生命周期数据服务:涵盖从数据湖/仓库的构建、热/温/冷数据的分层自动化管理,到长期归档的整体解决方案。
- 运维与可持续性服务:提供专业的监控、维护和扩展服务,同时关注绿色节能,降低庞大的AI基础设施的碳排放。
结论显而易见:在科教玩转AI的征途上,算力是“矛”,决定了冲击的高度与速度;而先进的全闪存储及配套的数据服务则是“盾”与“基石”,决定了冲击的持续性与稳定性。只有将二者协同升级,构建平衡、高效、敏捷的数据基础设施,才能真正释放AI的全部潜能,让科研探索与人才培养行稳致远,在这场智能革命中占据制高点。因此,当别人还在“卷”算力时,真正的行家已经开始“卷”存储和数据服务了,这正是一条从追赶迈向领先的必由之路。